

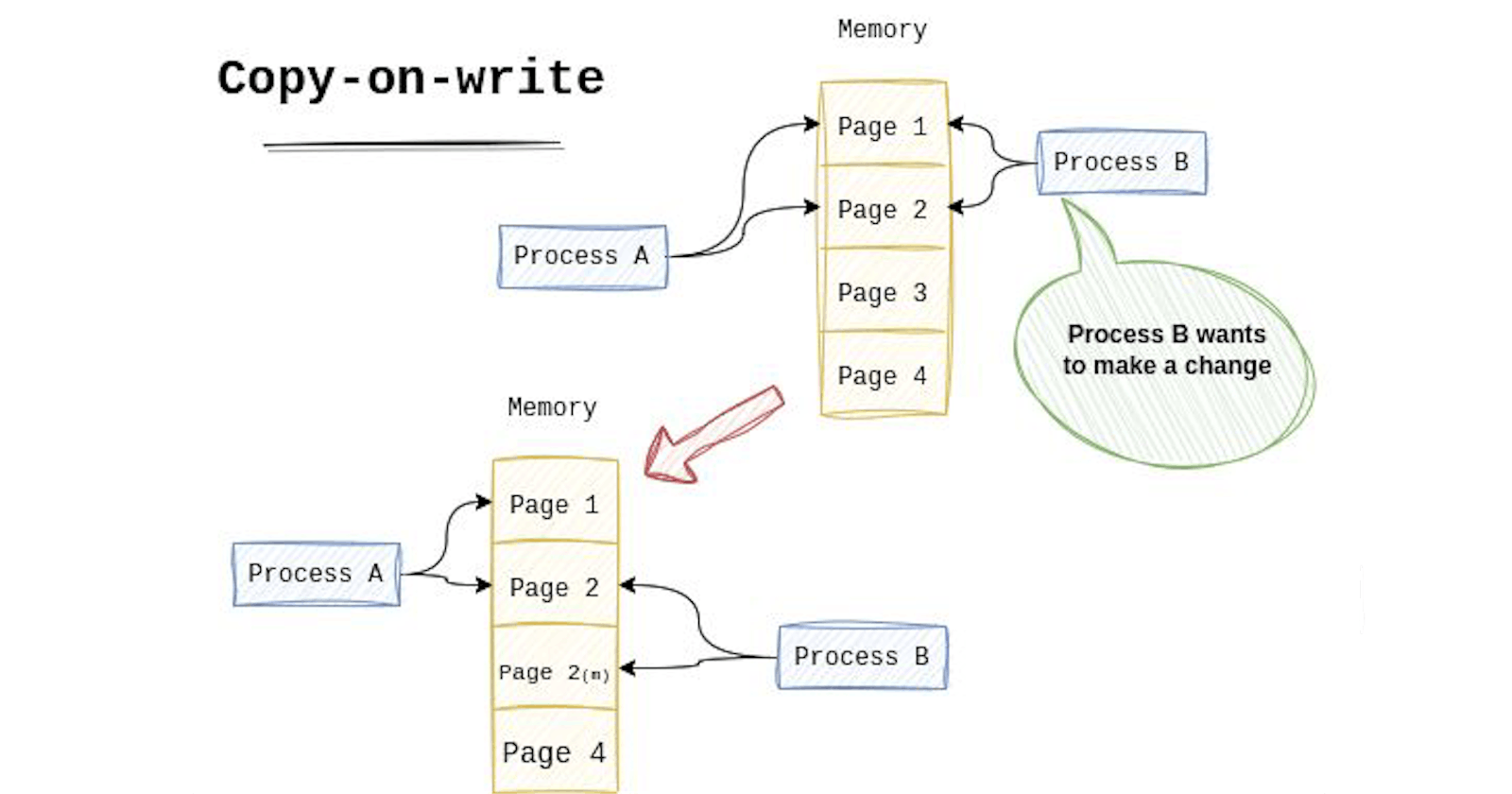
One of the widely used resource-management techniques is copy-on-write (COW). It is usually implemented when we have to copy or duplicate a resource (e.g., memory, files, and data structures).
It is implemented in one of the computer's fundamental parts, the Virtual Memory System (VMS). When the OS needs to copy a page (memory page) from one address space to another, instead of copying it immediately, it shares the page between both address spaces and marks it as read-only. And there you have it—a quick copy without duplicating the data.
But! And I know what you are thinking. What if one of the address spaces tries to write to the page? In this case, the OS is smart enough to recognize that this page is marked as COW, and it allocates memory for a new page. Then, it starts filling it with data before finally assigning it to the process that wants to make a change. This technique is useful when a process replaces its process image with exec() or creates a child process with fork(), an operation where a large address space needs to be copied.
Another place where this technique comes in handy is solving the file system’s crash consistency problem, which is the problem that can arise when a crash takes place while updating the on-disk file system. This can lead to damage to the file system’s data structure (trust me, we do not want this), leak space, etc.
One of the solutions to this problem is write-ahead logging (WAL), another one is (of course) copy-on-write. In this case, instead of overwriting files in place, we place new updates to unused locations on disk and after a number of updates, the file system flips the root structure of the file system to include pointers to the newly updated structures.
This technique also comes in handy when implementing snapshots for DBMS and in-memory caches like Redis, where copying large amounts of memory while updating is hard to implement without COW.